ChainerでTensor Coreを使ってみる
計算速度が一気に8倍速くなるらしいTensor Coreが使えるということで、昨年9月にTuring世代のGPUを買ってみたものの、Tensor Coreが簡単に使えて一気に早くなるわけでもなく、しばらくTensor Coreが使えているかどうかもよくわからない状態でした。今回一部修正もあって、Chainer v7.0.0a1でTensor Coreが使えることがほぼ確認できました。
また、Google ColaboratoryのGPUもTesla T4とTuring世代となり、Tensor Coreが使えそうなので試してみました。
環境
| 環境 | GPU | Cuda Core数 | FP32 | FP16 |
|---|---|---|---|---|
| 自宅PC | RTX 2080 | 2944個 | ※10.6 TFlops | ※85 TFlops |
| Colaboratory | Tesla T4 | 2560個 | 8.1 TFlops | 65 TFlops |
※推定値
3層 MNISTで試す
まずChainerのサンプルと同じ3層 全結合 MNISTで試してみました。
条件:
- Train:60000枚, Test:10000枚
- 3層:l1(784⇒1000) ⇒ l2(1000⇒1000) ⇒ l3(1000⇒10)
- batch:100枚, epoch:20回
Tensor Coreを使うには
chainer.global_config.dtype = np.float16
を入れれば、MNISTのデータも自動的にFP16に変換してくれているようで、全結合層ではどうやら自動的にTensor Coreが使われるみたいです。
3層MNIST結果(unit:1000, batch:100, @RTX2080)
| FP32 | FP16 | FP32/FP16 | |
|---|---|---|---|
| 計算時間 | 71.0秒 | 70.2秒 | 1.01倍 |
| 正答率 | 96.2% | 95.4% |
結果、全然早くなっていません。
この要因はサンプルのMNISTではGPUの行列計算よりも、CPUのその他いろいろな処理の方が遅いことにあるようです。CPUの負荷を下げるのは大変なので、とりあえずTensor Coreの効果をみるのに、GPUの行列計算の割合を増やした場合を試してみます。
6層 MNISTで試す
条件:
- Train:60000枚, Test:10000枚
- 6層:l1(784⇒4096) ⇒ l2(4096⇒4096) ⇒ l3(4096⇒4096) ⇒ l4(4096⇒4096) ⇒ l5(4096⇒4096)⇒ l6(4096⇒10)
- batch:4096枚, epoch:20回
隠れ層を4096ユニットにして、バッチを4096枚まで大きくして計算しました。
6層MNIST結果(unit:4096, batch:4096, @RTX2080)
| FP32 | FP16 | FP32/FP16 | |
|---|---|---|---|
| 計算時間 | 63.2秒 | 20.5秒 | 3.08倍 |
| 正答率 | 88.2% | 80.9% |
結果、約3倍まで早くなりました。
NVIDIA Visual Profiler(NVVP)を使ってFP16での計算のプロファイルを見てみました。
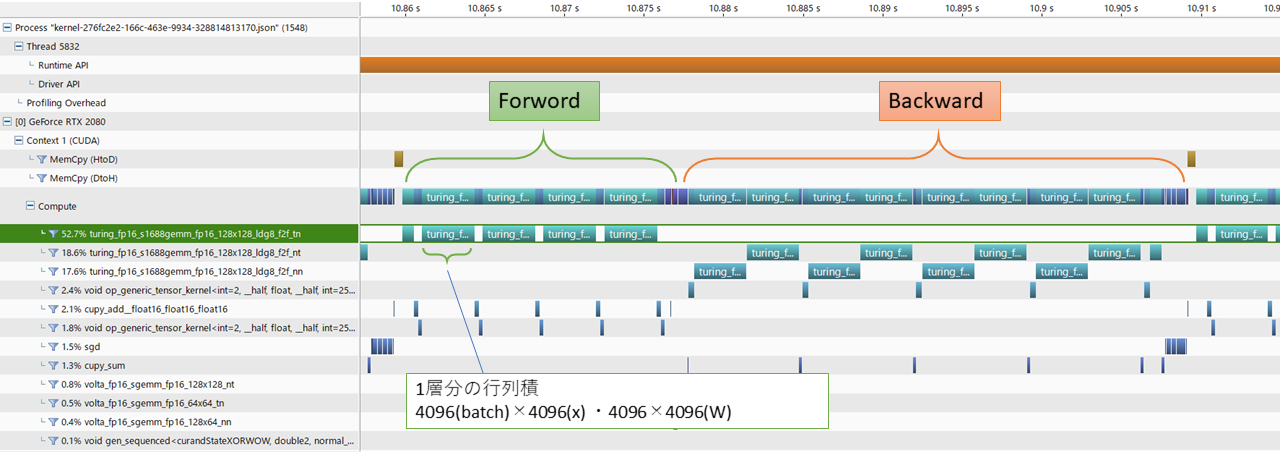
「turing_fp16_s1688gemm」の部分がどうやらTensor Coreでの計算部分のようです。2層目から5層目の4回分が一番計算負荷が高い「 4096(batch) × 4096(入力x) ・4096×4096(W)」の計算なので、その4回のforward計算の後、2×4回分のbackwardが続いているようです。
今回、Adamを使うとFP16でうまく計算ができなくなることがあったので、両方AdamではなくSGDを使っています。 学習率は変えないまま、batchを大きくしたので、20epoch中の学習する回数は少なくなり、正答率は下がっています。また、FP32に比べ、FP16の正答率が低いのは、FP16の桁が少ないことによるかもしれません。mixed16など使えば改善するかもしれませんが、今回はそのあたりは深入りしていません。
計算速度(TFlops)測定 (自宅PC/Colaboratory)
自宅PCとColaboratoryで、MNISTを使わずに単純な1層全結合だけの計算にて、計算速度(TFlops)を比較してみました。
Colaboratoryでは現在chainer v5.4.0があらかじめインストール済されていたので、
! pip uninstall chainer
! pip uninstall cupy-cuda100
! pip install cupy-cuda100 --pre
! pip install chainer --pre
にて最新のcupyとchainerを入れる必要がありますが、そのうちバージョンが上がれば必要なくなると思います。
# FP16 単層全結合 計算速度(TFlops)測定
import chainer
import chainer.functions as F
import numpy as np
import cupy as cp
import time
COUNT = 1000
N = 4096
x = np.random.uniform(size=(N, N))
W = np.random.uniform(size=(N, N))
x = chainer.Variable(cp.asarray(x,dtype= np.float16))
W = chainer.Variable(cp.asarray(W,dtype= np.float16))
start = time.time()
for i in range(COUNT):
y = F.linear(x, W, b=None, n_batch_axes=1)
print(y[0][0])
end = time.time()
elapsed = end - start
print('計算時間:{:.3f} s'.format(elapsed))
print('計算速度:{:.3f} TFlops'.format(1e-12* COUNT * 2*N*N*N / elapsed))
を実行することで、計算速度を出しています。TFlopsの計算速度はこちらを参考にしています。
計算速度比較 (unit:4096, batch:4096)
| 環境 | FP32 | FP16 | FP32/FP16 |
|---|---|---|---|
| 自宅PC RTX2080 | 9.4 TFlops | 40.0 TFlops | 4.26倍 |
| Colab Tesla T4 | 4.6 TFlops | 17.4 TFlops | 3.78倍 |
RTX2080にて、理論速度の85TFlopsの半分程度ではありますが、FP32に比べ4倍程度とTensor Coreの効果が出ていることが確認できました。Tensor Coreで8倍にならない理由はわかりませんが、こちらで何か勘違いしているかもしれません。
ColabのT4が遅いのは、T4のデフォルトのClockが抑えらえているなどあるかと思い、Clockの設定も少し試してみましたが、原因はよくわかりませんでした。
おわりに
ここで使ったコードはgithubに置いておきました。
よりTensor Coreを使いこなすにはNVIDIAさんの
がとても参考になると思います。今回全結合層でしたが、Convolutionを使う場合はチャンネルの並び(NHWC)とかも考慮しないと遅くなることがあるようです。
Chainerの対応などでTensor Coreを使うだけなら簡単にできるようになりました。しかしながら、FP32⇒FP16のコードを一行変えるだけで、手軽に今使っているネットワークの精度を落とさず数倍早くなるというわけでもなさそうです。実際Teonsr Coreが有効に使われているかはNVVPで計算のプロファイルを見ないとよくわかりません。NVVPでどこがボトルネックかを調べながら、バッチサイズや学習率などの調整やTeonsr Coreに配慮したコードへの改造が必要になってくると思います。